RAG for reliable AI: how to boost LLM response accuracy and reduce hallucination
RAG isn't a feature, it's how you make LLMs production-safe in regulated industries. What it actually does, where it fails, and how we ship it for fintech and healthcare workloads.
LLM hallucination is a system problem, not a model problem. Frontier models still hallucinate at non-trivial rates on long-tail factual queries, and no amount of prompt tuning fully fixes it. Retrieval-Augmented Generation (RAG) is the most reliable production pattern we've found for grounding LLM output in verifiable sources — and for any regulated workload (fintech, healthcare, legal, life sciences), it's the difference between an AI feature shipping and an AI feature getting rejected by compliance review.
This is the version of the RAG conversation we have with engineering leaders before scoping a GenAI project. What RAG actually is, where it wins, where it fails, and the production patterns we ship.
For deep-dive treatment of the failure modes specifically in fintech RAG — chunking on regulatory documents, audit trails, citation tracking, hallucination tolerance — see our companion piece on 10 RAG architecture mistakes fintechs make in production. And for a complete reference architecture in regulated finance, see /fintech/rag.
What RAG is, in production terms
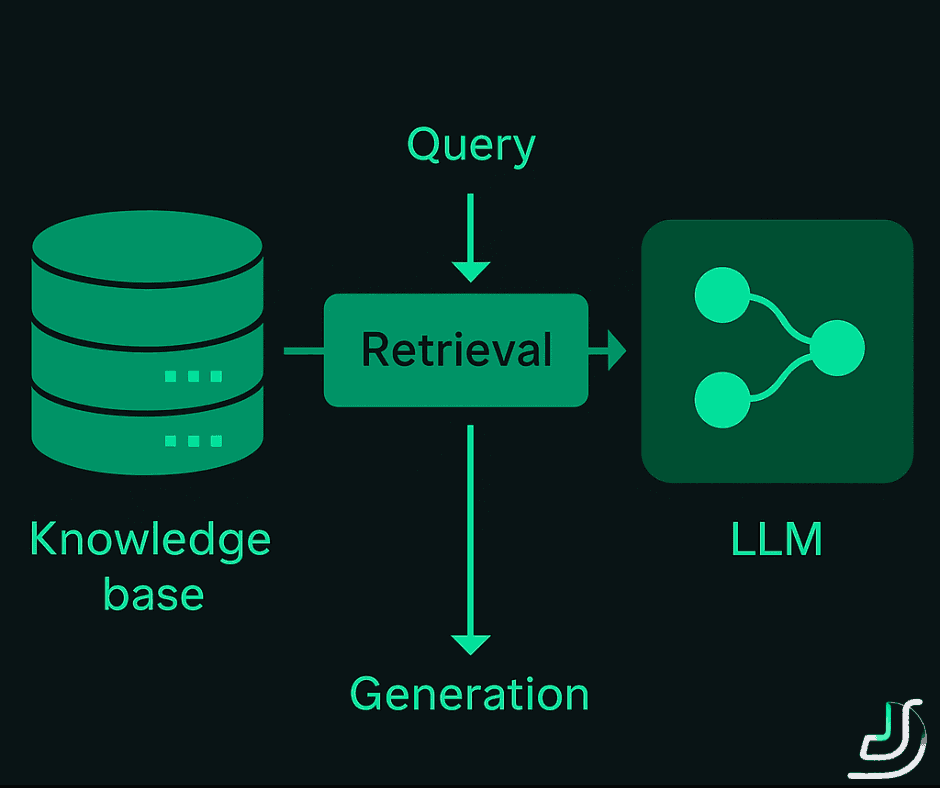
RAG is an architectural pattern: at query time, the system retrieves relevant context from a trusted knowledge base, then conditions the LLM's generation on that context plus the user's query. The model isn't asked to recall facts from training — it's asked to read what the retrieval system surfaced and answer from there.
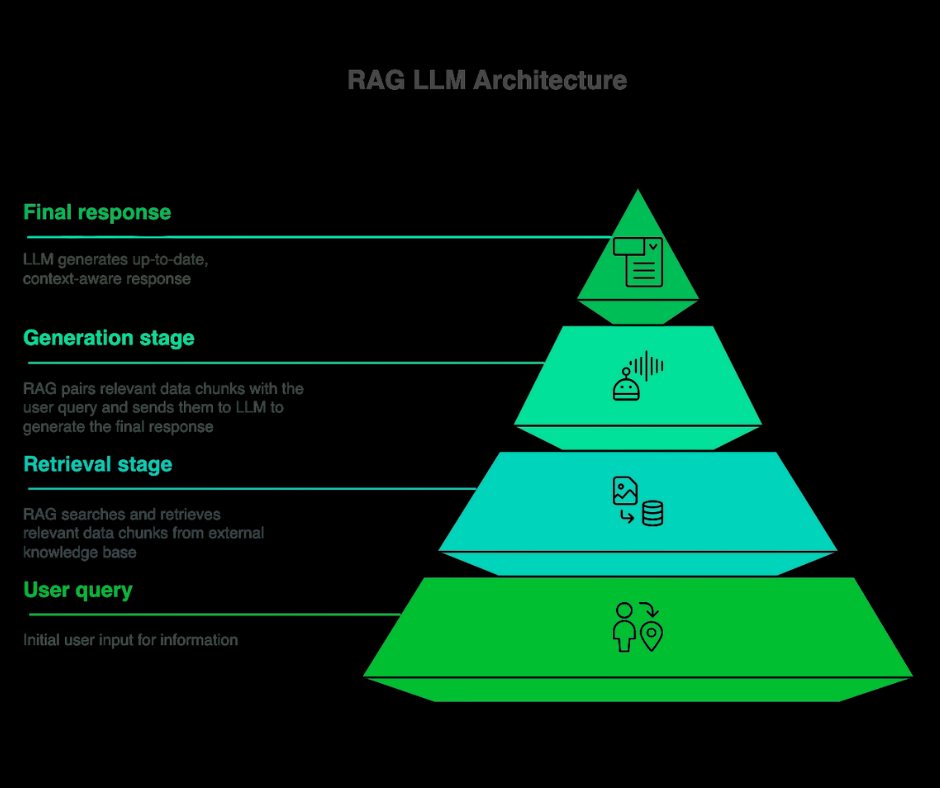
The seven components that make up a production RAG system:
- Ingestion — connectors pull from source systems (S3, SFTP, Confluence, document stores), with versioning and lineage
- Chunking — documents split into retrieval units (paragraph, section, semantic unit)
- Embedding — chunks vectorized via an embedding model (Voyage, OpenAI, Cohere, fine-tuned domain models)
- Vector store — embeddings indexed for similarity search (pgvector, Pinecone, Weaviate, Qdrant)
- Retrieval — query-time lookup combining vector similarity, keyword matching, and metadata filters
- Re-ranking — top candidates rescored for relevance (Cohere Rerank, fine-tuned cross-encoder)
- Generation — LLM reads the retrieved context and produces an answer with citations
The simple description hides production complexity. Each layer has trade-offs that determine whether the system delivers ground-truth answers or whether retrieval misses, citations are wrong, and hallucinations creep back in. We've documented those in detail in our fintech RAG mistakes article.
What RAG actually solves
Three concrete problems that matter for production deployments:
Hallucination on factual queries. Studies and our own engagement data both show RAG sharply reducing hallucination rates on grounded tasks. A peer-reviewed study on structured table generation reported RAG reducing hallucination from 21% to 4.5% — a roughly 4× reduction. We see similar magnitude improvements on regulatory Q&A workloads when retrieval and reranking are tuned properly. RAG doesn't eliminate hallucination — the model can still misread or fabricate around retrieved context — but it shifts the error distribution sharply toward "I don't know" and away from confident-incorrect.
Knowledge cutoff and stale answers. Foundation models are trained on data up to a fixed cutoff and have no knowledge of events after. For any workload that depends on current information — market data, regulatory updates, internal knowledge that changes weekly — fine-tuning every quarter is impractical. RAG retrieves from a live index that you update on your schedule. The model becomes the reasoning layer, not the storage layer.
Domain adaptation without retraining. Generic LLMs underperform on specialized domains where vocabulary, context, and nuance matter. Fine-tuning addresses this, but it's expensive and the resulting model is a static asset that needs maintenance. RAG sidesteps the problem: you connect the model to your proprietary corpus (technical manuals, support logs, compliance docs, case law) and the retrieval layer surfaces what the model needs at query time. New documents are added by indexing them, not by retraining.
RAG vs fine-tuning
Both approaches improve accuracy and relevance, but they trade off differently. We use both, and the decision is workload-specific — not a one-size answer.
| Dimension | Fine-tuning | RAG |
|---|---|---|
| Training cost | High — annotated data, GPU time, retraining cycles | Low — index documents, no model retraining |
| Inference cost | Low — no external lookups | Adds retrieval cost (vector + reranker) |
| Inference latency | Fast — fully internal | +30–50% from retrieval and rerank |
| Adaptability | Low — retrain to add knowledge | High — index new docs anytime |
| Knowledge source | Static, embedded in weights | Dynamic, fetched at query time |
| Domain accuracy | High in narrow trained domains | Depends on retrieval quality |
| Data privacy | Weaker — data baked into model | Stronger — data stays in customer-controlled storage |
| Best for | Stable specialized environments with static knowledge | Dynamic or regulated environments needing real-time data |

The honest production answer is almost always hybrid. Fine-tune the model for domain vocabulary and tone (or fine-tune the embedding model — often the higher-leverage move). Then layer RAG on top for current factual grounding. For complex regulated workloads — legal research, medical Q&A, fintech compliance — the combined pattern outperforms either approach alone.
When to choose RAG-only: the domain knowledge changes faster than retraining cycles, data residency rules out fine-tuning on customer-controlled hardware, the application needs auditable citations, or you don't have the labeled data volume needed for high-quality fine-tuning.
When to choose fine-tuning-only: the workload is narrow, latency is the dominant constraint (sub-100ms p99), the knowledge surface is small and stable, and you have a clean dataset of 10K+ task-specific examples.
Production RAG in practice
A few public references for how this looks at scale.
Healthcare. RAG-augmented diagnostic systems consistently outperform base models on grounded medical reasoning. A RAG-boosted GPT-4 deployment for gastrointestinal diagnosis from imaging reached 78% accuracy, a 24-point improvement over base GPT-4, and produced at least one correct differential diagnosis 98% of the time. The RECTIFIER system for clinical trial screening reached 93.6% overall accuracy on the COPILOT-HF trial — outperforming the human staff baseline of 85.9%. IBM Watson's RAG-driven oncology system matched expert recommendations in 96% of cases when tested.
Legal research. Vincent AI, a RAG-enabled legal tool, was tested by law students across six legal assignments — productivity gains of 38% to 115% on five of six tasks. LexisNexis uses RAG architecture to continuously integrate new legal precedents into its LLM tools — case law that's added to the index becomes citable at query time without retraining.
Financial services. Wells Fargo deploys Memory RAG for analyzing complex financial documents during earnings calls — reported 91% accuracy with average 5.76s response time. Bloomberg's analyst products use RAG-driven LLMs to generate summaries of news and financial reports for institutional clients. Both deployments share the same constraint: source citations and audit trails are non-negotiable, which RAG provides natively and fine-tuning doesn't.
The pattern across all three industries: RAG is the architecture that makes LLMs deployable when correctness is verifiable and the cost of confident-wrong is high.
Where RAG goes wrong
Four failure modes we see across engagements:
Incomplete or irrelevant retrieval. The knowledge base doesn't contain the answer, or the retriever surfaces tangentially related chunks. The model then either fabricates a confident answer from the wrong context or generates a generic non-answer. Fix is upstream: corpus coverage audit, hybrid retrieval (vector + BM25 + metadata filters), and a reranker tuned on a domain-specific eval set.
Ineffective context use. The right chunks are retrieved, but chunking is bad — content split mid-clause, table integrity broken, context window stuffed with redundant chunks. Critical facts get ignored or misread. Fix is document-type-aware chunking (regulatory PDFs respect clause boundaries, transactional logs chunk by event, structured docs preserve table integrity) and retrieval-window tuning.
Misleading output despite correct retrieval. The model hallucinates around correct context, or amplifies subtle wording differences in the prompt. Fix is prompt design, output filtering, refusal templates, and an evaluation harness that catches drift between prompt versions before it reaches production.
Operational overhead and scale limits. RAG adds system complexity, observability requirements, and ongoing maintenance. Without proper design — vector index sizing, embedding model selection, reranker latency budget — costs and latency creep up. We've documented the cost economics in detail in our fintech RAG architecture reference.
Best practices for production RAG
Four practices we treat as defaults on every RAG engagement:
Curate the source corpus before indexing. A messy knowledge base produces bad retrieval no matter how good the model is. Remove obsolete content, resolve contradictions, standardize formats, add metadata (source, version, effective date, jurisdiction). Automate freshness reviews — stale data drives hallucinations even when the architecture is correct. In regulated industries, lineage isn't optional: every chunk traces back to a source document, version, and effective date for SOX, PCI-DSS, and SR 11-7 audits.
Document-type-aware chunking. Generic 512-token splitters are the most common cause of fintech RAG failure in production. Regulatory PDFs need section-aware splitting that respects clause boundaries. Transactional logs chunk by logical event. Structured docs preserve table integrity. Match chunking strategy to document structure, not the other way around.
Fine-tune the embedding model. Out-of-the-box embeddings are trained on general language and miss domain-specific terminology — exact identifiers (CUSIP, ISIN, drug codes), regulation citations, internal jargon. Fine-tuning the embedding model on your corpus shifts retrieval quality more than almost any other intervention. Pair with hybrid retrieval (vector + BM25) for cases where keyword matching is faster and more accurate than semantic similarity.
Monitor retrieval quality continuously. RAG isn't set-and-forget. Track which chunks are retrieved for which queries, and how that affects final answers. Run an evaluation harness on every model, prompt, or retrieval change — hallucination rate, citation accuracy, refusal rate, latency p99 are deployment gates, not afterthoughts. Close the loop with chunking adjustments, embedding retraining, and prompt refinement.
What's next for RAG
Three production directions we're watching and increasingly shipping:
Multimodal RAG (MRAG). Retrieval and generation across text, images, video, and audio in a single pipeline. Real-world content — webpages, multimedia documents, technical manuals — increasingly distributes information across modalities. MRAG handles each modality natively rather than text-extracting first.
Self-correcting RAG loops. When the LLM's answer diverges from retrieved context, a verification step catches the divergence and retriggers retrieval with a refined query. Converts RAG from one-way data flow into iterative reasoning. Expensive, but valuable for high-stakes workloads where confident-wrong is costly.
RAG + SLMs at the edge. Pairing retrieval with small language models for on-device, on-prem, or air-gapped deployment. The SLM provides the reasoning layer; RAG provides the knowledge. Combined: a private, low-latency, residency-compliant AI system that runs without cloud dependency. We see this pattern increasingly in healthcare, finance, and government workloads.
FAQs
What are the main benefits of using RAG in LLMs? RAG grounds LLM responses in verifiable external information, reducing hallucination, providing dynamic knowledge updates, and enabling source citations. For regulated workloads, the citation capability is often the deciding factor — auditors need to trace what the system told whom, when, and why, and RAG provides that natively.
Can RAG eliminate hallucination? No, but it sharply reduces it. Studies and our own engagements show 3–5× reductions in hallucination rate on grounded tasks. The remaining hallucinations come from the model misreading retrieved context or fabricating around it — hence the importance of evaluation harnesses, citation accuracy metrics, and refusal templates that prefer "I don't know" over plausible-but-wrong answers.
Is RAG effective for real-time or fast-changing information? Yes — this is one of RAG's strongest use cases. The retrieval layer pulls from a live index, so any document or data added today is queryable tomorrow without retraining. This is the entire reason finance, news, and customer support deployments default to RAG over fine-tuning.
How does RAG integrate with existing AI workflows? RAG is modular. Typical integration: stand up a vector store, build the ingestion + chunking + embedding pipeline, wire retrieval into the prompt construction step before the LLM call, and add citation tracking on the output. With clean data and a defined eval set, a RAG MVP ships in 8–12 weeks. Production-grade systems with full audit trails and golden-set evaluation take 16–20 weeks.
Should I use RAG, fine-tuning, or both? Almost always both, in some proportion. Fine-tune the embedding model for domain vocabulary; layer RAG for current grounded knowledge. Pure fine-tuning fits narrow stable domains; pure RAG fits dynamic regulated environments. The hybrid pattern dominates serious production deployments.
Ready to ship production-grade RAG? Run the Project Estimator for a deterministic ballpark, book a 45-minute Discovery with our AI engineers, or read the full reference architecture for fintech RAG.
Talk to the team behind this
Building something like this in production?
Our senior engineers ship this kind of work for real teams. 45-minute call, no pitch deck — just architecture, trade-offs, and whether we're the right fit for your problem.










