Building a recommendation engine: a production engineering guide
What it actually takes to build a production-grade recommendation engine — the three filtering approaches, four implementation paths, six-step build process, and the failure modes that block deployment.

Recommendation engines drive 80%+ of Netflix viewing and similar revenue percentages on Amazon, Spotify, YouTube, TikTok. The market opportunity is real — but most enterprise teams building their first recommendation engine ship something that underperforms in production. The gap is rarely technology; it's scoping discipline, data quality, and operational maturity.
This article maps what it takes to ship a production-grade recommendation engine — the three filtering approaches, four implementation paths, six-step build process, and the failure modes to plan for. For broader ML cost framing, see calculating machine learning costs.
Recommendation engine fundamentals
Three primary filtering approaches with different production trade-offs.
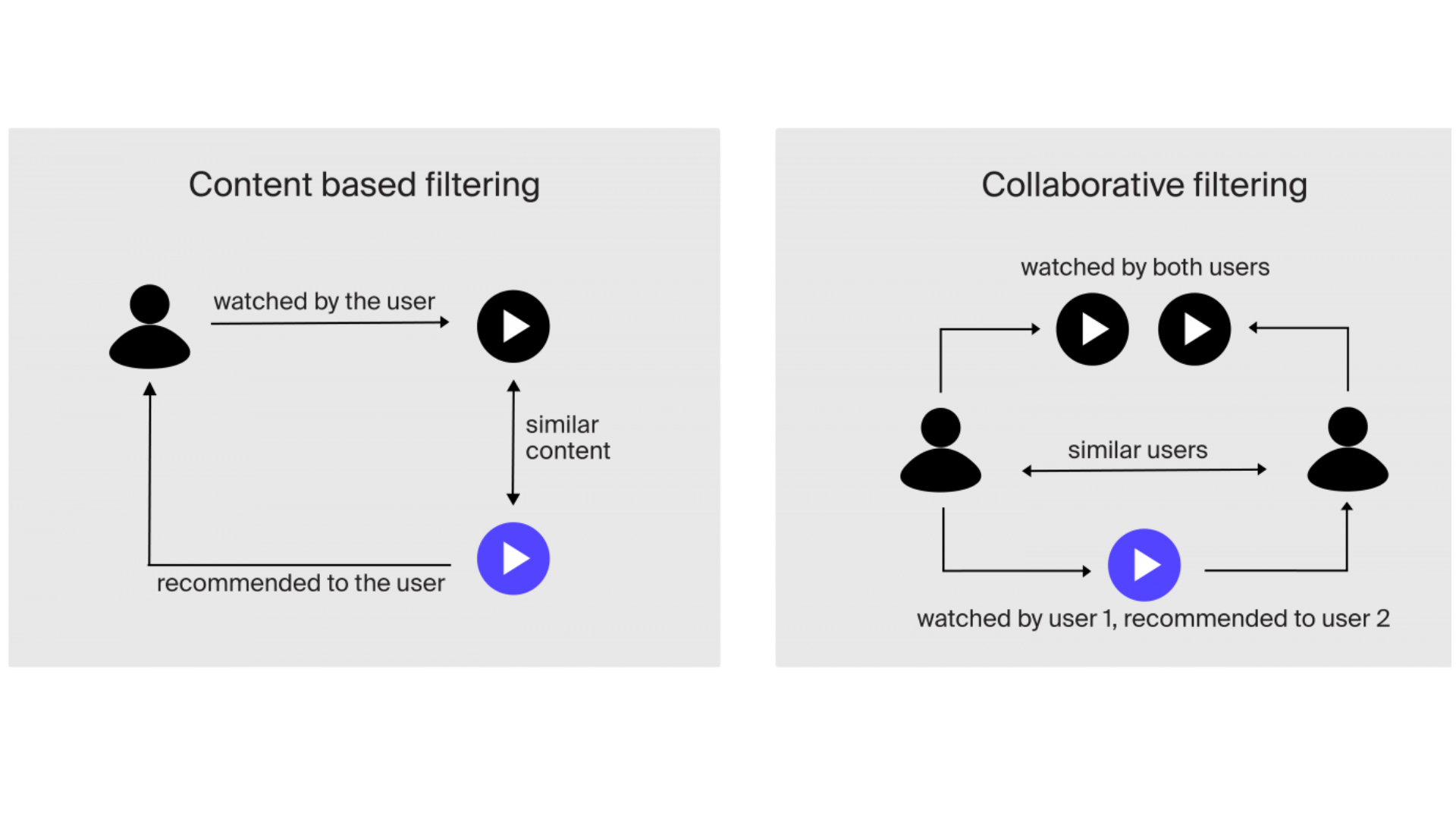
Content-based filtering
Recommends items similar to those a user has liked before, based on item attributes. A user who watches sci-fi action movies gets recommended more sci-fi action movies. Item attributes — genre, director, cast, themes — are extracted and compared.
Strengths: works for new users with no behavior history (cold start friendly on user side). Doesn't require behavior data from other users. Recommendations are explainable ("you liked X, this is similar").
Weaknesses: narrow — recommends only things similar to what the user already knows. Limited diversity. Cold start problem on items (new items with no attributes can't be recommended).
Collaborative filtering
Recommends items that similar users liked. "Users who liked X also liked Y." Doesn't require item attributes — works on user behavior patterns alone.
Strengths: discovers diverse recommendations beyond user's existing patterns. Works well at scale with rich behavior data. Surfaces serendipitous matches.
Weaknesses: cold start on both users (new users have no behavior) and items (new items have no interactions). Requires substantial user behavior data. Computational cost grows with users × items.
Hybrid approaches
Most production recommendation engines combine both. Content-based handles cold start; collaborative drives diversity at scale. Modern systems often add deep learning layers (neural collaborative filtering, transformer-based recommendation) and contextual signals (time of day, location, device).
The pattern: pick the simplest approach that hits accuracy targets, layer in additional approaches as scale and data quality justify them.
Recommendation engine use cases
Four categories driving production deployment:
Content discovery. Netflix, Spotify, YouTube — recommending content from large catalogs. Higher engagement, lower churn, more time on platform.
Product recommendations in ecommerce. Amazon's "customers who bought this also bought" pattern. Drives basket size, conversion rate, repeat purchases.
Personalized advertising and marketing. Showing different content, products, or offers based on user attributes and behavior. Drives click-through, conversion, retention.
Internal recommendations. Tools recommending the right reports to executives, the right resources to support staff, the right next actions in CRM systems. Less visible than consumer-facing recs but high-leverage for enterprise productivity.
Four implementation paths

1. Plug-and-play recommendation engines
Off-the-shelf platforms (Recombee, Optimove, Salesforce Personalization, Algolia Recommend) provide turnkey recommendation infrastructure. Integration cost: $10K–$50K plus recurring license fees.
Best for: quick deployment, validation of recommendation hypothesis, smaller catalog sizes, standard use cases. Limitations: customization is bounded; vendor lock-in; recurring fees scale with usage.
2. Pre-trained cloud-based recommendation services
Cloud-based ML services (AWS Personalize, Google Cloud Recommendations AI, Azure Personalizer) handle infrastructure and provide managed model training. Integration cost: $20K–$80K plus per-recommendation costs.
Best for: mid-size deployments wanting cloud-managed infrastructure. Trade-off: less customization than fully custom builds; cloud vendor lock-in; cost scales with usage.
3. Custom recommendation engines
Build the recommendation system from scratch — algorithm selection, training infrastructure, serving layer, monitoring. Total cost: $80K–$500K+ depending on scope.
Best for: unique data structures, specialized domains, full control over recommendations, IP ownership. Trade-off: highest upfront cost and longest deployment timeline; requires senior ML expertise.
4. Hybrid (custom + platform)
Most production deployments combine custom recommendation logic with platform capabilities. Custom handles unique business rules and core recommendations; platform handles standard infrastructure (A/B testing, feature stores, real-time serving).
Six-step process for building a recommendation engine
Step 1. Set direction
Before any technology decision, answer:
- What's the business goal? Revenue per user, engagement time, conversion rate, retention rate, average order value
- What's the success metric? Specific numerical target with baseline
- Where will recommendations appear? Homepage, product pages, search, email, push notifications
- What's the latency budget? Real-time (sub-200ms) vs near-real-time (seconds) vs batch (hours)
- What data is available? User behavior, item attributes, contextual signals, demographic data
The discipline that separates successful recommendation projects from pilots: clear answers to these before any algorithm choice.
Step 2. Gather training data
For collaborative filtering: explicit feedback (ratings, reviews) plus implicit feedback (clicks, views, purchase history, time on page, scroll depth). Most modern recommendation engines rely heavily on implicit feedback because explicit feedback is sparse.

For content-based filtering: item attribute extraction. Manual tagging (slow but accurate), automated extraction from text/images (faster but noisier), categorization taxonomies. Modern systems increasingly use vision-language models to extract rich item embeddings automatically.
Data volume matters more than feature richness for many recommendation use cases. Hundreds of thousands of interactions typically beats hundreds of features per item.
Step 3. Clean and process data
Common preprocessing tasks:
- Handle missing values — imputation, flagging, or filtering
- Deduplicate interactions — multiple clicks within seconds shouldn't all count
- Filter outliers — bots, accidental views, abandoned sessions
- Normalize ratings — different users use rating scales differently
- Handle implicit feedback bias — popular items get more interactions, but that doesn't mean every interaction is positive signal
This step routinely consumes 30–40% of project time. Skip it and the model trains on noise.
Step 4. Choose an optimal algorithm
The algorithm landscape:
Classical algorithms:
- Matrix factorization (SVD, NMF)
- K-nearest neighbors (KNN) with various similarity metrics
- Association rules (Apriori, FP-Growth)
- Logistic regression with engineered features
Deep learning approaches:
- Neural collaborative filtering
- Wide & Deep models
- Two-tower architectures
- Sequence models (LSTM, transformer-based)
- Graph neural networks
Modern approaches:
- LLM-augmented recommendations (using foundation models for content understanding)
- Hybrid retrieval-and-rerank pipelines (similar to RAG patterns — see our RAG article)
- Multi-task learning across related objectives

For most enterprise applications: start with simpler algorithms (matrix factorization, KNN) for baseline. Validate accuracy on real data. Move to deep learning only when complexity is justified by accuracy gains and deployment scale.
Step 5. Train and validate the model
Training infrastructure:
- Single-node training for smaller models
- Distributed training for larger models or larger datasets
- Cloud ML platforms (Vertex AI, SageMaker, Azure ML) for managed infrastructure
Validation strategy:
- Holdout validation: split user-item interactions chronologically (train on history, validate on future)
- Cross-validation for smaller datasets
- Online A/B testing for production validation
Critical: validate against business metrics, not just model accuracy. A model with 5% better RMSE may have 20% lower conversion if it recommends technically-similar but commercially-uninteresting items.
Step 6. Tune hyperparameters
Hyperparameter optimization can move accuracy 10-20% on the same model architecture. Strategies:
- Grid search (exhaustive but expensive)
- Random search (often more efficient)
- Bayesian optimization (best for expensive training runs)
- Population-based training (for evolving hyperparameters during training)
In production, automate this. Manual hyperparameter tuning doesn't scale.
Three challenges that block production deployment
1. Measuring success
The hardest part of recommendation engineering isn't building the model — it's knowing whether the model actually works. Common pitfalls:
- Optimizing offline metrics that don't predict online performance. RMSE on held-out interactions doesn't directly translate to revenue or engagement.
- Confounded A/B tests. Recommendation effects often interact with seasonality, marketing campaigns, product launches.
- Long-term vs short-term effects. A recommendation that drives click-through but not retention is a false positive on success metrics.
Mitigation: define multi-metric success criteria upfront. Run A/B tests with sufficient traffic and duration to detect long-term effects. Monitor leading indicators (click-through, engagement) and lagging indicators (revenue, retention) together.
2. The curse of dimensionality
When item catalogs are large and user behavior data is sparse, computational complexity becomes a binding constraint. Naive approaches that work for 10K items × 100K users break down at 1M items × 100M users.
Mitigation: dimensionality reduction (matrix factorization, embeddings), sparse data structures, retrieval-and-rerank pipelines (fast retrieval narrows candidates, expensive ranking applies to top-N), distributed serving infrastructure.
3. Cold start
New users (no behavior history) and new items (no interaction data) are hard to recommend for in collaborative filtering systems.
Mitigation:
- For users: content-based fallback using demographic/contextual signals; popularity-based recommendations until behavior data accumulates
- For items: content-based extraction from item attributes; cold start exploration where new items get displayed deliberately to gather initial interaction data
- Hybrid approach: combine collaborative filtering for known users/items with content-based for cold start
Production deployment patterns
Beyond the build, six engineering practices that determine whether the system scales:
Real-time serving infrastructure. Sub-200ms inference latency through caching, pre-computation, and approximate nearest neighbor search (FAISS, ScaNN, HNSW). Modern recommendation systems serve from vector databases or specialized inference engines.
Feature stores. Centralized feature engineering and serving. Tecton, Feast, AWS SageMaker Feature Store, Vertex Feature Store. Critical when feature engineering complexity grows.
A/B testing infrastructure. Random user assignment, metric collection, statistical significance testing. Most teams underestimate this — running rigorous A/B tests is engineering work, not just statistics.
Continuous training and retraining. Models drift as user behavior shifts. Automated retraining pipelines on a schedule (weekly, daily, or even hourly for fast-moving domains).
Monitoring and alerting. Watch for accuracy drift, recommendation diversity, fairness across user segments, infrastructure health.
Compliance and governance. GDPR, CCPA, sector-specific regulations affect what data you can use and what disclosures users need. Build compliance into the architecture, don't retrofit.
Three implementation cost ranges
Small recommendation engine (single use case, plug-and-play platform, simple integration): $30K–$80K initial + recurring fees.
Mid-size custom recommendation engine (custom algorithm, dedicated infrastructure, basic A/B testing): $150K–$400K initial + $30K–$60K annual maintenance.
Enterprise recommendation platform (multi-use-case, real-time serving, advanced ML, governance, A/B testing infrastructure): $500K–$1M+ initial + $100K–$200K annual.
For broader cost framing across ML projects, see calculating machine learning costs and how much does AI cost in 2026.
Final framing
Building a production recommendation engine is engineering work. The algorithms are documented. The infrastructure patterns are mature. The failure modes are known. What separates the recommendation engines that drive measurable revenue from the ones that quietly underperform is operational discipline — clear success metrics, rigorous A/B testing, continuous retraining, monitoring infrastructure, governance frameworks.
The teams that succeed with recommendation engines treat them as products with ongoing operations, not projects with a launch. The compound benefits over years are substantial — but they require investment that doesn't always look exciting in roadmap presentations.
Ready to scope a recommendation engine project? Run the Project Estimator for a deterministic ballpark, or book a 45-minute Discovery with our ML engineers — we'll review your data, business goals, and integration surface and tell you honestly which implementation path fits your scope and timeline.
Talk to the team behind this
Building something like this in production?
Our senior engineers ship this kind of work for real teams. 45-minute call, no pitch deck — just architecture, trade-offs, and whether we're the right fit for your problem.










