Federated learning: your guide to collaborative AI
Federated learning trains AI on distributed data without centralizing it — solving the privacy/innovation trade-off. How it works, where it ships in production (healthcare, finance, mobile), and the implementation discipline.

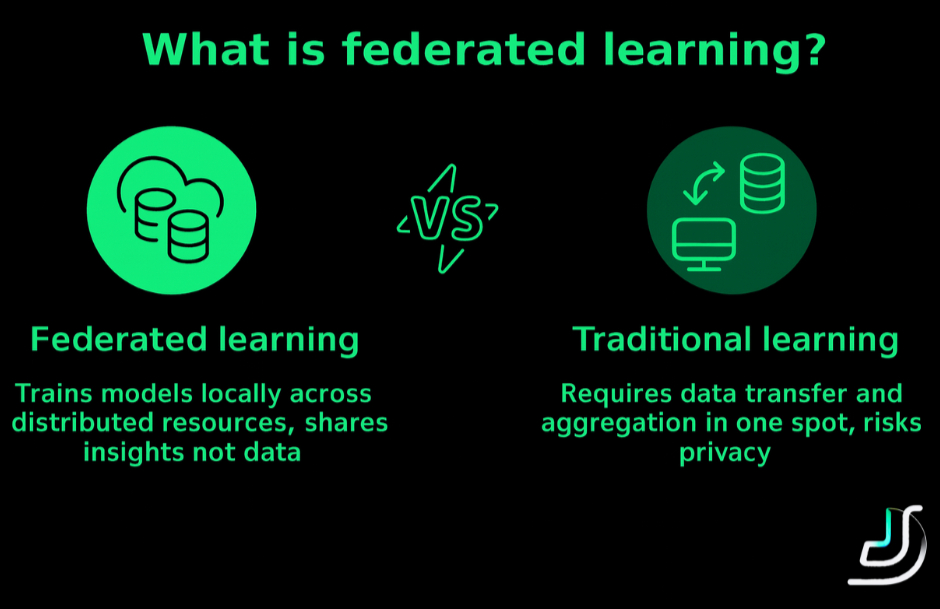
Traditional AI systems require all data in one place — creating privacy exposure, compliance headaches, and reputational risk. Federated learning offers a different architecture: train AI on distributed data without ever centralizing it. The model travels to the data, not the other way around. Privacy is preserved by design, not by retroactive policy.
For regulated industries (healthcare under HIPAA, finance under SR 11-7, EU deployments under GDPR/AI Act), federated learning isn't just a privacy win — it's increasingly the only viable architecture for cross-organization AI collaboration. Multiple hospitals can train a diagnostic model together without sharing patient data. Multiple banks can train fraud detection together without sharing transaction details.
This article maps what federated learning actually is, how it works in production, where it ships, and the implementation discipline. For broader treatment of LLM training and adaptation strategies, see LLM training stages.
What federated learning actually is
Federated learning is a distributed machine learning approach where models train across multiple devices or organizations without exchanging raw data. Instead of centralizing data for training, the model travels to where the data is. Each participant trains the model locally on their own data, then shares only model updates (gradient information or parameter updates) with a central coordinator. The coordinator aggregates these updates to improve the global model, which is redistributed back to participants.
The result: collaborative AI that benefits from data diversity across organizations while keeping each organization's raw data inside their own infrastructure.
Three types of federated learning
1. Centralized federated learning. A central coordinator manages the global model, distributes it to participants, and aggregates their updates. Most common pattern in production. Examples: hospital networks training shared diagnostic models, mobile keyboards training shared autocompletion models.
2. Decentralized federated learning. No central coordinator. Participants exchange model updates peer-to-peer or via blockchain-based coordination. More resilient against single-point-of-failure but operationally complex.
3. Cross-silo federated learning. Designed for collaboration between organizations (silos) rather than across millions of devices. Each silo represents a substantial dataset and computation capability. Common in healthcare consortia, banking partnerships, research collaborations.
How federated learning works in production
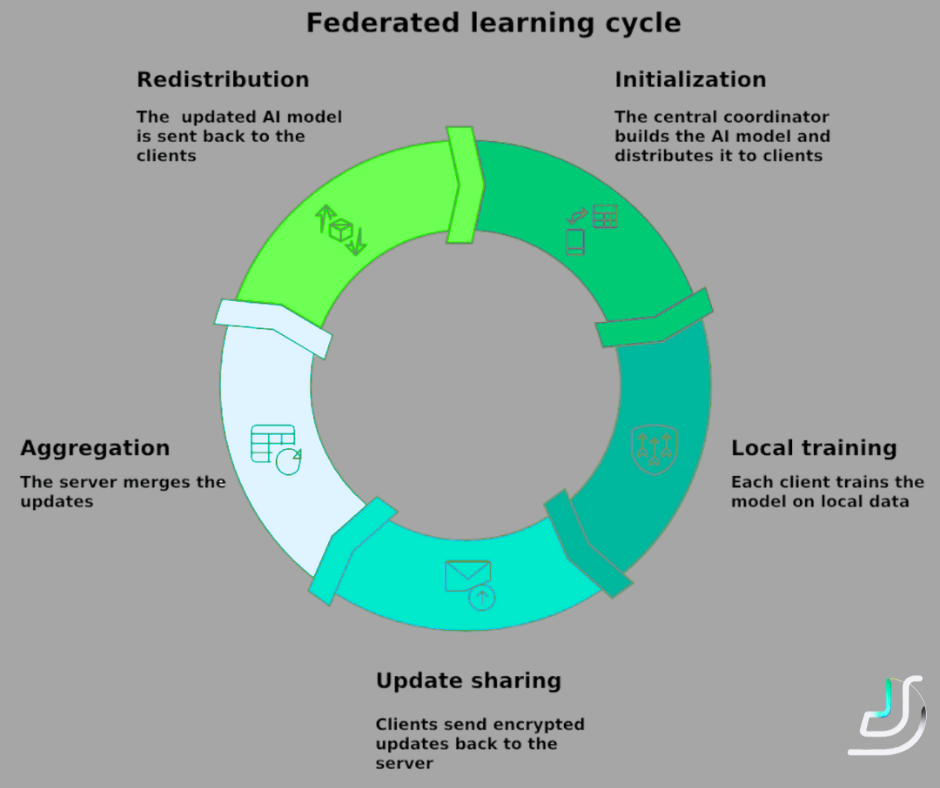
The five-step cycle:
Step 1: Initialization. Central coordinator distributes the initial model architecture and starting parameters to all participants.
Step 2: Local training. Each participant trains the model on their local data. Model parameters update based on local patterns. Raw data never leaves the participant's infrastructure.
Step 3: Update sharing. Participants send only model updates (typically gradient information or parameter deltas) back to the coordinator. The updates contain no raw data — they're statistical summaries of how the model should change based on local training.
Step 4: Aggregation. Coordinator combines updates from all participants using techniques like Federated Averaging (FedAvg). Privacy-preserving techniques (differential privacy, secure aggregation) prevent reconstruction of individual data from the updates.
Step 5: Redistribution. Updated global model goes back to all participants. The cycle repeats — local training, update sharing, aggregation, redistribution — until model performance stabilizes.
Federated learning frameworks
Three production frameworks dominate:
TensorFlow Federated (TFF). Google-developed framework for federated machine learning research and production. Strong for cross-device federated learning at large scale. Tight integration with TensorFlow ecosystem. Best for organizations already in the TF stack.
PySyft. Privacy-preserving ML framework with federated learning support. Strong cryptographic primitives (homomorphic encryption, secure multi-party computation). Best for healthcare and finance where formal privacy guarantees are critical.
Flower (FLwr). Open-source, framework-agnostic. Works with PyTorch, TensorFlow, JAX, scikit-learn, NumPy. Production-friendly with good operational tooling. Best for organizations wanting flexibility across ML frameworks.
The right framework depends on existing ML stack, privacy requirements, and operational maturity. Most production deployments evaluate all three before committing.
Real-world strategic impact
Six categories where federated learning ships in production:
Healthcare
Privacy regulations (HIPAA, GDPR for EU patients) make centralizing patient data across institutions difficult or impossible. Federated learning enables hospital networks to train diagnostic models together while keeping patient data within each hospital's infrastructure.
Reference deployments: NVIDIA Clara federated learning platform, MELLODDY consortium for drug discovery, federated COVID-19 diagnostic models trained across hospital networks.
Outcomes: diagnostic models trained on far more diverse patient populations than any single hospital could provide, with privacy preserved end-to-end.
Financial services
Banks training fraud detection models benefit from diverse fraud patterns across institutions, but transaction data can't be shared due to competitive and regulatory constraints. Federated learning enables collaborative fraud model training without data sharing.
Reference deployments: WeBank's FATE federated learning framework for finance, federated AML (anti-money laundering) consortia, federated credit scoring across financial institutions.
Outcomes: improved fraud detection accuracy, faster identification of new fraud patterns, lower regulatory risk than centralized data sharing approaches.
Mobile devices
Google's keyboard (Gboard) uses federated learning to improve text prediction across billions of devices without sending typing data to servers. Apple uses similar approaches for Siri and on-device AI features.
Outcomes: personalized AI on user devices, privacy preserved through on-device training, lower bandwidth than cloud-only alternatives.
Manufacturing and industrial IoT
Manufacturing networks training predictive maintenance models benefit from anomaly patterns across multiple facilities, but operational data is competitively sensitive. Federated learning enables industry-wide pattern detection while keeping plant-level data private.
Outcomes: more robust predictive maintenance models, faster identification of equipment failure patterns, competitive intelligence preserved.
Research collaborations
Academic and research collaborations train ML models across institutional datasets without violating data sharing agreements or research ethics constraints. Particularly valuable in genomics, neuroscience, and other domains with strict data protection requirements.
Reference deployments: UK Biobank federated research collaborations, Brain Imaging Data Structure (BIDS) federated analyses, federated neuroimaging research networks.
Telecommunications
Telecom networks training anomaly detection, traffic prediction, and customer experience models across geographic regions and operator boundaries.
Outcomes: better network performance prediction, faster identification of attacks and anomalies, regulatory-friendly architecture in jurisdictions with data localization requirements.
Federated learning examples in healthcare
Two specific deployments that anchor the abstract patterns:
Pancreatic cancer detection across 20+ hospitals. A federated learning consortium trained a pancreatic cancer detection model on imaging data from 20+ hospitals across multiple countries. No patient data left any individual hospital. Resulting model achieved diagnostic accuracy that no single hospital could have reached alone — because each contributed unique patient population diversity to the training process.
Federated COVID-19 diagnostic models. During the pandemic, multiple research collaborations trained COVID-19 diagnostic models across hospital networks using federated learning. Hospitals contributed model improvements without sharing patient images. Resulting models worked across diverse populations with strong generalization, deployed faster than centralized data-sharing approaches would have allowed.
For deeper treatment of healthcare AI patterns including federated learning, see /industries/healthcare and benefits of AI in healthcare.
Implementation challenges
Five challenges to plan for in production federated learning deployments:
1. Communication overhead. Federated learning requires multiple rounds of model updates between participants and coordinator. At scale, communication cost can exceed compute cost. Mitigation: gradient compression, sparse updates, smart sampling of which participants to include in each round.
2. Heterogeneous data and devices. Participants may have different data distributions, sample sizes, hardware capabilities, network connectivity. The global model must work well for all participants, not just average performance. Mitigation: personalized federated learning, fairness-aware aggregation, robust optimization.
3. Privacy attacks. Despite the privacy-by-design framing, sophisticated attacks can sometimes reconstruct training data from model updates. Mitigation: differential privacy (adding controlled noise to updates), secure aggregation (cryptographic protocols that hide individual updates), homomorphic encryption.
4. Regulatory ambiguity. Federated learning is newer than many regulatory frameworks. Some questions (whether model updates count as personal data, jurisdictional implications of cross-border updates) remain legally unresolved. Mitigation: legal review specific to your deployment jurisdiction, conservative data handling pending regulatory clarification.
5. Operational complexity. Federated learning systems are more complex to deploy and operate than centralized ML. More moving parts, more failure modes, more coordination overhead. Mitigation: experienced ML engineering team, mature operational tooling, gradual rollout starting with small-scale collaboration before scaling to many participants.
When to use federated learning vs alternatives
Decision framework:
Choose federated learning when:
- Data residency requirements rule out centralized training
- Multiple organizations want to collaborate on AI without sharing data
- Privacy regulations make data centralization difficult or impossible
- Devices have meaningful local computation capability
- Data diversity across participants creates value beyond what any single participant has
Choose centralized training when:
- All training data is already accessible centrally
- Computational resources favor centralized infrastructure
- Operational complexity of federated systems doesn't justify privacy benefits
- Single organization owns all relevant data
Choose alternative privacy-preserving approaches when:
- Differential privacy alone provides sufficient privacy
- Synthetic data generation can substitute for real data sharing
- Homomorphic encryption fits the specific computation pattern
- Trusted execution environments (Intel SGX, AWS Nitro Enclaves) provide adequate isolation
For deeper treatment of training strategies, see LLM training stages and few-shot learning.
Final framing
Federated learning is the architecture that emerges when privacy regulations meet the value of collaborative AI training. It's not a research curiosity — it's shipping in healthcare, finance, mobile, manufacturing, telecommunications, and research collaborations today.
The implementation complexity is real. The privacy guarantees require careful architectural attention. The operational discipline matters. But for use cases where data centralization isn't viable, federated learning is increasingly the right answer — and the gap is widening as privacy regulations expand and AI capabilities mature.
Ready to evaluate federated learning for your AI project? Run the Project Estimator for a deterministic ballpark, or book a 45-minute Discovery with our AI engineers — we'll review your privacy constraints, data architecture, and collaboration goals to determine whether federated learning fits your specific use case.
Talk to the team behind this
Building something like this in production?
Our senior engineers ship this kind of work for real teams. 45-minute call, no pitch deck — just architecture, trade-offs, and whether we're the right fit for your problem.











