How to create an AI system: a practical guide for business owners
What it actually takes to build an AI system from scratch — the tech stack decisions, build-vs-buy framework, five-step process, and the discipline that separates shipping projects from stalled pilots.

Building an AI system is engineering work with established patterns — but most business owners scoping their first AI project make decisions that doom delivery before any code gets written. The most common failures aren't technical: wrong build-vs-buy decision for the use case, unrealistic timeline expectations, missing data foundation, no walk-away discipline, no operational plan after launch.
This article maps what it actually takes to create a production AI system — the tech stack decisions, the build-vs-buy framework, the five-step development process, and the discipline that separates shipping projects from stalled pilots. For broader AI cost framing, see how much does AI cost in 2026 and how to implement AI in business.
AI subtypes and what they do for business
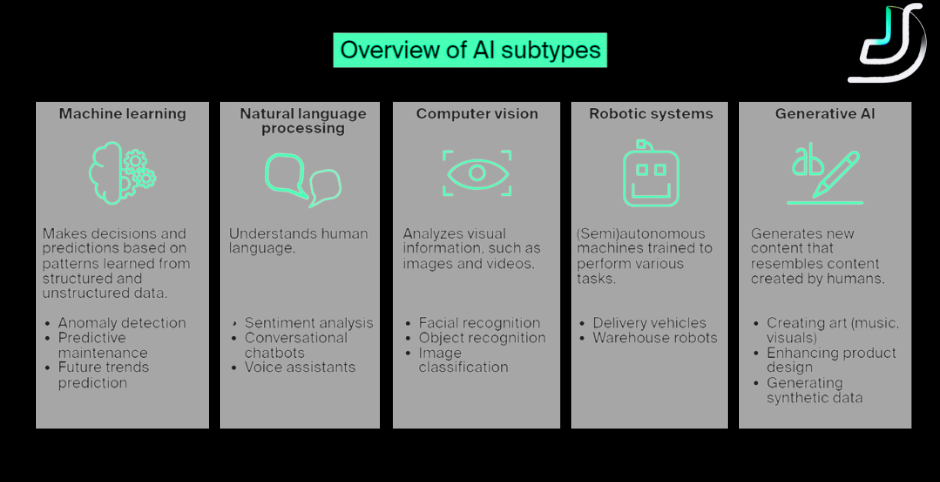
The AI capability landscape:
- Machine learning. Pattern detection and prediction from historical data. Workhorses for fraud detection, recommendation systems, predictive maintenance, demand forecasting. See calculating ML costs.
- Natural language processing. Understanding and generating human language. Foundation for chatbots, document processing, sentiment analysis, content moderation.
- Computer vision. Interpreting visual information. See computer vision applications across industries.
- Generative AI. Creating new content (text, images, audio, video). See generative AI vs AI.
- Agentic AI. Autonomous systems that plan and execute multi-step workflows. See what are AI agents.
Most production AI systems combine multiple subtypes — classical ML for analytical workloads, GenAI for content tasks, computer vision for visual data, agents for multi-step workflows. The right combination depends on workload.
What AI can do for business in 2026
Six concrete value categories where production AI consistently delivers ROI:
- Process automation. Document processing, invoice handling, customer service routing
- Predictive analytics. Demand forecasting, customer churn, equipment failure
- Quality and anomaly detection. Manufacturing inspection, fraud, security threats
- Personalization at scale. Product recommendations, content suggestions, marketing optimization
- Content generation. Drafting, summarization, translation, creative content
- Decision support. Surfacing insights, flagging risks, recommending actions
The pattern: AI delivers value when matched to specific workflows with measurable cost or revenue baselines. AI as "let's add intelligence" rarely captures meaningful value.
How AI projects differ from traditional software development
Five differences that matter for scoping:
Probabilistic vs deterministic. Traditional software produces predictable outputs from given inputs. AI produces probabilistic outputs that may vary. This requires different testing, monitoring, and governance approaches.
Data is the asset. Traditional software ships with the code. AI ships with the model, which depends on training data quality. Data preparation routinely consumes 25-40% of AI project budget.
Continuous evolution. Traditional software ships, maintains, occasionally updates. AI systems drift as data and behavior shift, requiring continuous retraining and monitoring.
Accuracy isn't binary. Traditional features either work or don't. AI features have accuracy levels that affect business outcomes — 90% vs 95% can be a meaningful business impact.
Operational discipline matters more. Traditional software can run unattended for years. AI requires ongoing MLOps work — model monitoring, drift detection, retraining cycles, governance reviews.
The implication: AI project planning needs different patterns than traditional software project planning. The teams that ship successful AI deployments treat it as ongoing operational capability, not one-time build.
Build vs buy framework
Three primary paths for acquiring AI capability:
1. Use ready-made AI models
Pre-built solutions accessed via APIs (Claude, GPT, AWS Comprehend, Google Vision, Azure Cognitive Services). Off-the-shelf SaaS products with embedded AI.
Cost: integration work ($10K-$80K) plus recurring licensing or per-API fees.
Best for:
- Standard use cases (sentiment analysis, OCR, language translation)
- Quick validation before custom investment
- Workloads where customization isn't strategic
- Smaller-scale deployments where economics favor SaaS
Limitations: vendor lock-in, limited customization, recurring fees, data goes through vendor infrastructure.
2. Customize ready-made models
Fine-tune existing foundation models on your data. Use platforms like AWS SageMaker, Google Vertex AI, Azure ML, or open-source frameworks (Hugging Face).
Cost: $40K-$250K depending on model complexity and customization depth.
Best for:
- Domain-specific accuracy requirements
- Proprietary data that creates competitive advantage
- Mid-volume deployments where economics shift
- Want some control without full custom build
Limitations: still depends on foundation model availability; vendor relationship for hosting; fine-tuning expertise required.
3. Build from scratch
Custom architecture, training infrastructure, deployment pipeline. Total ownership of model, data, and IP.
Cost: $150K-$1M+ depending on scope.
Best for:
- Highly specialized domains where commercial models don't fit
- Unique data structures that require custom architecture
- Strategic competitive advantage from AI ownership
- Regulated workloads where vendor dependencies create compliance risk
- Long-term cost optimization at scale
Limitations: highest upfront cost; longest deployment timeline; requires senior ML expertise; ongoing operational burden.
When custom from-scratch makes sense
Custom AI development from scratch is rarely the right first move. It's the right path when:
- Your workload is genuinely unique and commercial models don't fit
- You have the specialized data needed to train better than foundation models
- The use case is core to competitive advantage
- The deployment scale justifies the upfront investment
- Regulatory or data residency requirements rule out vendor dependencies
- You have or can hire the senior ML talent required
For most enterprises, the right path is sequenced: API as-is for validation → fine-tuned models for production → custom build only when scale and strategic importance justify it.
Tech stack options
Programming languages and libraries
Python dominates AI development. The ecosystem is mature, community is large, libraries are comprehensive.
- Foundational ML: scikit-learn, XGBoost, LightGBM
- Deep learning: PyTorch, TensorFlow, JAX
- NLP: Hugging Face Transformers, spaCy, NLTK
- Computer vision: OpenCV, torchvision, MMDetection
- GenAI: LangChain, LlamaIndex, Anthropic SDK, OpenAI SDK
- Vector databases: pgvector (Postgres extension — see our pgvector vs Pinecone benchmark), Pinecone, Qdrant, Weaviate
Other languages used:
- C++ for performance-critical inference
- Rust increasingly for high-performance ML serving
- Go for ML infrastructure and serving layers
- JavaScript/TypeScript for client-side inference (TensorFlow.js, ONNX Web)
Deployment options
Cloud platforms:
- AWS (SageMaker, Bedrock, Comprehend, Rekognition)
- Google Cloud (Vertex AI, Generative AI Studio)
- Azure (Azure ML, Azure OpenAI Service)
- Specialized AI clouds (Modal, Together AI, Replicate)
On-premises:
- Customer-controlled infrastructure for data residency
- GPU racks (NVIDIA A100, H100, L40S)
- Managed Kubernetes for orchestration
Edge:
- On-device inference for latency-critical workloads
- Specialized hardware (Jetson, Coral, Hailo)
- See edge AI article
Hybrid:
- Cloud for training and centralized analytics
- Edge for inference and real-time decisions
- Most production deployments use hybrid architectures
The choice depends on data residency requirements, latency budget, scale economics, and operational maturity. Most enterprises start with cloud and migrate to hybrid as scale or compliance demands grow.
Five-step process for creating an AI system
Step 1: Define the business problem
Specific workflow with measurable success criteria, not "we want AI." Apply the same discipline outlined in how to implement AI in business:
- One specific workflow
- Clean baseline metrics
- Specific financial or operational targets
- Walk-away criteria pre-committed
- Executive ownership for outcomes
Step 2: Aggregate and clean data
Data is the foundation. Realistic time allocation: 25-40% of project budget on data work.
- Source identification. Internal databases, SaaS platforms, external APIs, public datasets, customer data
- Acquisition — purchasing commercial datasets, licensing internal data, scraping (with legal review), synthetic data generation
- Cleaning — handling missing values, deduplication, normalization, outlier handling
- Labeling — manual annotation, semi-supervised, automated with human review
- Validation — quality checks, bias auditing, distribution analysis
- Versioning — version control for datasets to enable reproducible experiments
For deeper treatment of data engineering work, see /services/data-engineering.
Step 3: Build/buy the AI model
The build-vs-buy decision documented in the framework above. For most enterprise projects:
- Start with off-the-shelf models for validation
- Move to fine-tuning when domain accuracy demands customization
- Build from scratch only when strategic importance and scale justify the investment
For deeper treatment of fine-tuning vs RAG vs from-scratch decisions, see LLM training stages.
Step 4: Train and evaluate
Training infrastructure depends on model size and data volume:
- Single-node for smaller models that fit on one GPU
- Distributed training for larger models or larger datasets
- Cloud ML platforms for managed training infrastructure
Evaluation discipline:
- Holdout validation — split data chronologically, train on history, validate on future
- Cross-validation for smaller datasets
- Multi-metric evaluation — accuracy, calibration, fairness, business impact metrics
- Online A/B testing for production validation
Critical: validate against business metrics, not just model accuracy. A model with 5% better RMSE may have lower business impact if it recommends technically-similar but commercially-uninteresting items.
Step 5: Deploy and monitor
Deployment patterns:
- Real-time inference APIs for transactional workflows
- Batch processing for periodic analysis
- Stream processing for continuous data flows
- Edge deployment for latency-critical workloads
Monitoring infrastructure:
- Model performance monitoring — accuracy drift, prediction distribution shifts
- Infrastructure monitoring — latency, throughput, resource utilization
- Business metric monitoring — revenue impact, conversion rate changes, user engagement
- Drift detection — input distribution changes, output behavior shifts
- Alerting — automated alerts on threshold breaches
- Observability — full request tracing for debugging production issues
For deeper treatment of MLOps, see /services/ai-genai/mlops.
Production discipline that separates winners
Five practices that consistently produce shipping AI systems:
- MVP-first. One workflow, validated success metrics, 12-24 weeks build, real users for testing
- MLOps from day one. Versioning, automation, monitoring, retraining built into initial development
- Continuous evaluation. Eval harnesses with golden sets, automated regression testing, human review on edge cases
- Walk-away discipline. Pre-committed failure criteria, willingness to shut down projects that don't hit gates
- Compound investment. Each successful deployment builds infrastructure and expertise that accelerates the next
Final framing
Creating an AI system is engineering work with documented patterns, mature tools, and clear failure modes. The teams that ship successful AI systems treat it as disciplined engineering with operational discipline, not as research or one-time projects.
The capabilities of AI in 2026 are real and substantial. The competitive advantage compounds for companies that invest now in the engineering discipline to deploy AI systems reliably. The gap between AI Leaders and AI Laggards is widening, and the lead time to catch up is measured in calendar quarters of disciplined investment.
Ready to scope an AI system project? Run the Project Estimator for a deterministic ballpark, or book a 45-minute Discovery with our AI engineers — we'll review your business goals, data foundation, and operational readiness, and tell you honestly whether to start with off-the-shelf, fine-tuning, or custom build.
Talk to the team behind this
Building something like this in production?
Our senior engineers ship this kind of work for real teams. 45-minute call, no pitch deck — just architecture, trade-offs, and whether we're the right fit for your problem.











