AI and machine learning in bioinformatics: a practical guide
Where AI and ML are genuinely shipping in bioinformatics — five production use cases driving genomics, proteomics, and drug discovery, with the implementation patterns and challenges to plan for.

The pace of bioinformatics research is now bottlenecked by data analysis, not data generation. DNA sequencing that took 13 years for the original human genome now completes in a day. Single-cell RNA sequencing produces datasets with billions of measurements per experiment. Modern genomics, proteomics, and drug discovery generate orders of magnitude more data than human researchers can manually analyze — and that's where AI and machine learning become essential infrastructure.
This article maps where AI and ML are genuinely shipping in bioinformatics today — five production use cases with measurable impact, the techniques that work, and the implementation challenges to plan for. For broader healthcare AI framing, see /industries/healthcare. For deeper treatment of healthcare AI cost, see assessing the cost of implementing AI in healthcare.
Machine learning techniques used in bioinformatics
Six core ML techniques dominate bioinformatics applications:
Natural language processing
NLP processes scientific literature at scale — research papers, clinical notes, drug labels, regulatory filings. Bioinformatics applications include literature mining for drug target discovery, automated systematic review, biological named entity recognition (genes, proteins, diseases, drugs), and semantic search across millions of papers.
Modern bioinformatics NLP uses domain-specific models (BioBERT, SciBERT, PubMedBERT) trained on biomedical literature, often combined with retrieval-augmented generation for grounded reasoning over scientific corpora.
Neural networks
Deep learning architectures — CNNs for image data, RNNs/Transformers for sequential data, graph neural networks for molecular structures — underlie most modern bioinformatics breakthroughs.
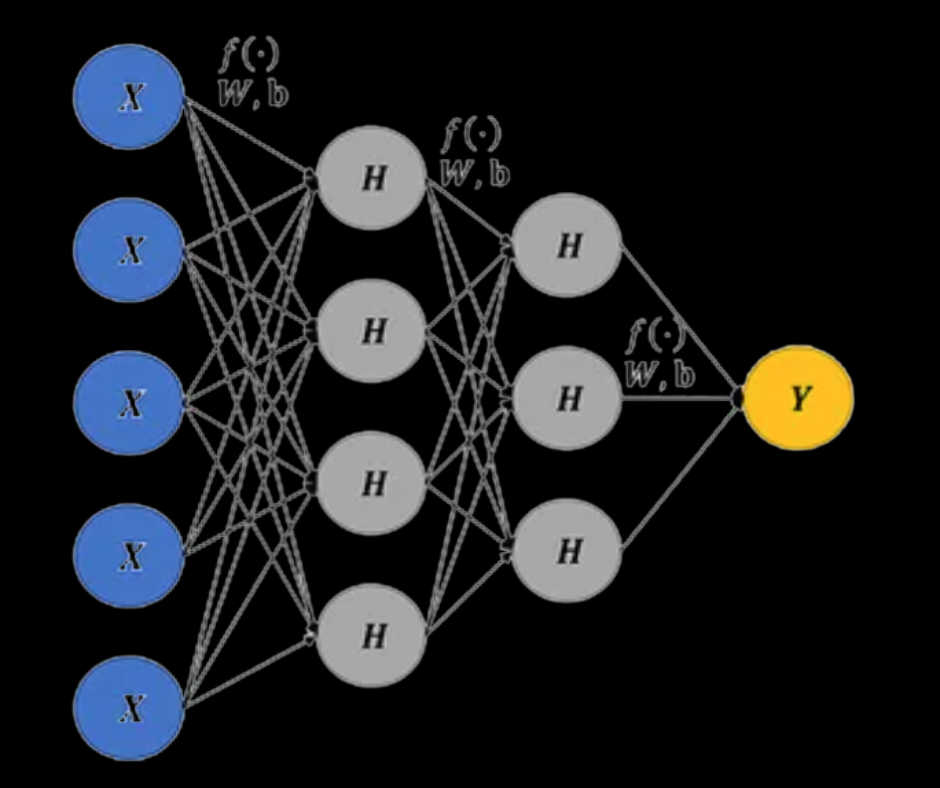
DeepMind's AlphaFold (winner of the 2024 Nobel Prize in Chemistry) is the canonical example: predicts 3D protein structures from amino acid sequences with experimental-grade accuracy. AlphaFold 2 alone has predicted structures for 200+ million proteins, roughly a 200x expansion of the structural biology dataset.
Clustering
Unsupervised learning groups biological data points by similarity. Applications: cell type discovery in single-cell RNA sequencing, patient subtype identification in disease research, identifying functional modules in gene expression data.
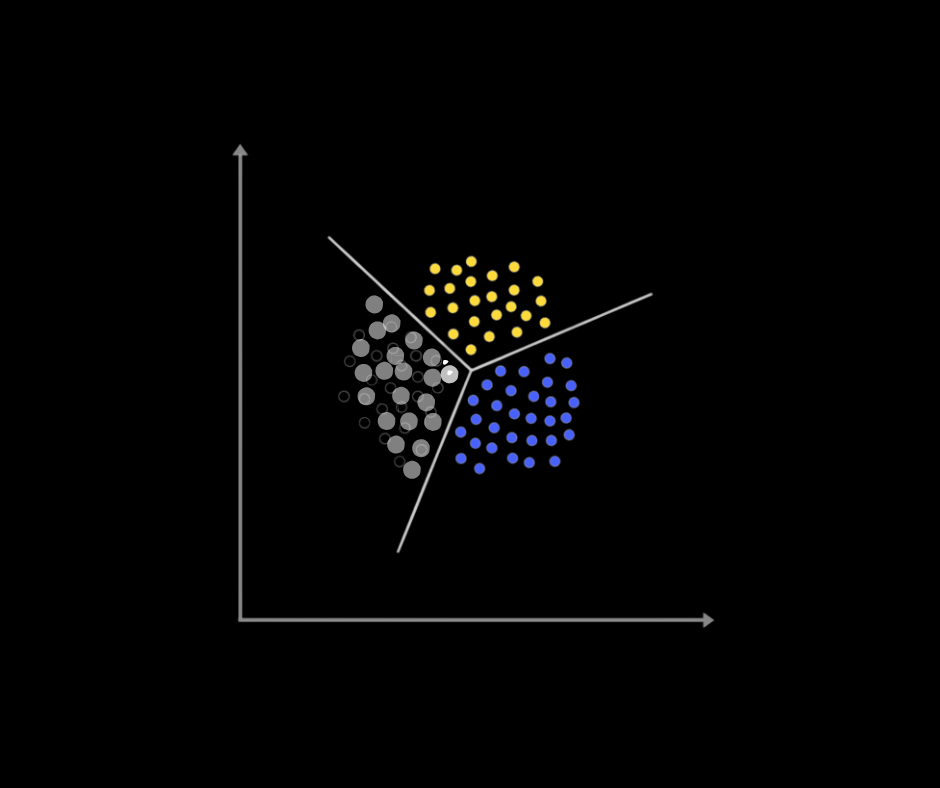
Common algorithms: K-means for simple cases, hierarchical clustering for nested structure, DBSCAN for irregular shapes, modern approaches like UMAP and t-SNE for high-dimensional visualization.
Dimensionality reduction
Bioinformatics data is often extremely high-dimensional — tens of thousands of genes, millions of single-nucleotide variants, multiple omics layers per sample. Dimensionality reduction techniques (PCA, UMAP, t-SNE, autoencoders) make this data analyzable and visualizable.
These techniques are foundational to single-cell genomics, multi-omics integration, and exploratory analysis of complex biological datasets.
Decision tree classifiers
Tree-based models (Random Forests, gradient boosting) work well on structured biological data. Applications: predicting drug response from genomic profiles, classifying cancer subtypes, identifying biomarkers for disease.
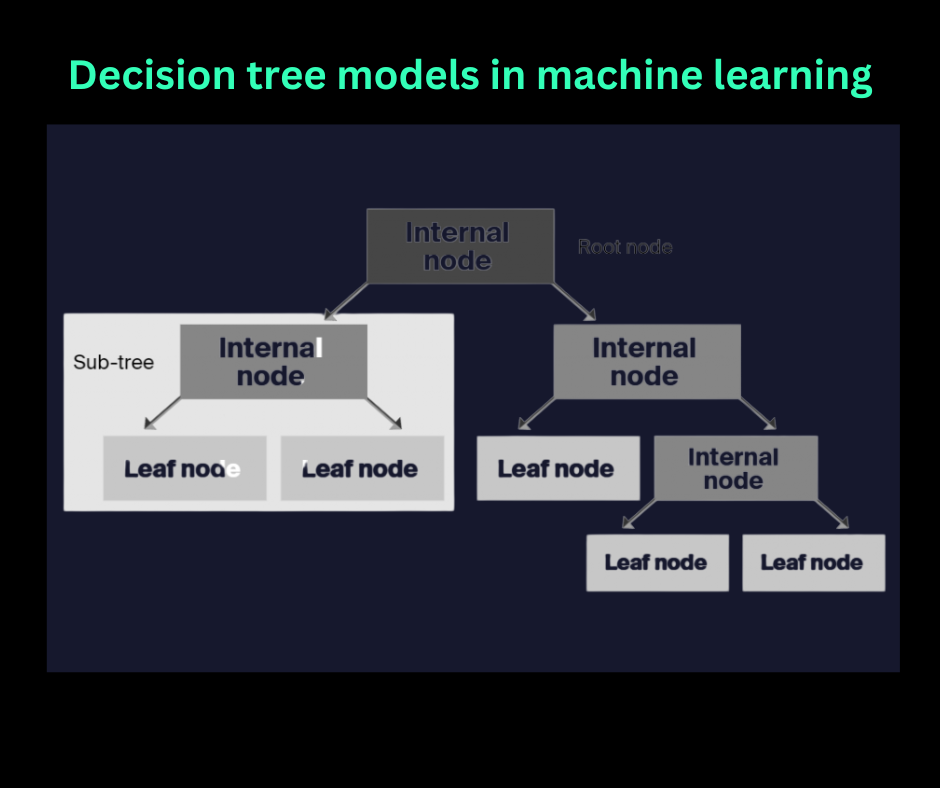
Strengths: interpretable feature importance, handle mixed data types, work well with smaller datasets common in clinical research.
Support vector machines
SVMs remain useful for bioinformatics classification tasks despite the rise of deep learning. Applications: protein function prediction, splice site identification, peptide-protein interaction prediction.
Particularly effective when sample sizes are smaller than feature dimensions — a common situation in clinical genomics.
Five production use cases
1. Facilitating gene editing experiments
CRISPR-based gene editing requires careful guide RNA design to maximize on-target editing while minimizing off-target effects. ML models trained on experimental data predict guide RNA efficiency and specificity, dramatically accelerating gene editing experiments.
Reference deployments: DeepCRISPR, CRISPOR, CRISPR-DAV — production tools used by gene editing labs globally. Saves weeks of empirical optimization per gene target.
Outcomes: faster gene editing experiments, higher success rates, reduced off-target effects, broader application of CRISPR in research and therapeutics.
2. Identifying protein structure
Protein structure determines protein function, but determining structures experimentally is slow and expensive. AlphaFold 2 and related models predict 3D protein structures from amino acid sequences with accuracy approaching experimental methods.
Production impact: structures predicted for 200+ million proteins, accelerating drug discovery, enzyme engineering, and basic biological research. Recent advances (AlphaFold 3, RoseTTAFold All-Atom) extend predictions to protein-ligand and protein-protein interactions.
Outcomes: faster drug discovery cycles, better understanding of disease mechanisms, expanded druggable target landscape.
3. Spotting genes associated with diseases
Genome-wide association studies (GWAS) identify genetic variants associated with diseases. ML models extend traditional GWAS by handling complex non-linear relationships, integrating multi-omics data, and identifying disease-relevant gene networks rather than individual variants.
Reference deployments: UK Biobank ML analyses identifying disease-associated variants across millions of participants. Multi-omics integration platforms identifying disease subtypes from combined genomic, transcriptomic, and proteomic data.
Outcomes: discovery of disease mechanisms, identification of new therapeutic targets, better disease subtyping for precision medicine, earlier disease risk prediction.
4. Traversing biological knowledge bases
Modern biological databases (UniProt, NCBI GenBank, PDB, ChEMBL) contain hundreds of millions of entries. ML-powered semantic search and pattern discovery surface relationships that manual analysis can't uncover.
Reference deployments: Causaly's agentic AI for biomedical knowledge synthesis (90% time savings on target identification), Atomwise's AI drug discovery platform, BenevolentAI's drug repurposing platform.
Outcomes: faster hypothesis generation, drug-target relationship discovery, identification of clinical trial candidates, systematic literature review at scale.
5. Repurposing drugs
Existing approved drugs may have therapeutic potential beyond their initial indications. ML models predict potential new uses based on molecular structure, biological pathway data, and clinical evidence.
Reference deployments: BenevolentAI identified Eli Lilly's baricitinib as a potential COVID-19 treatment; clinical trials confirmed effectiveness. Recursion's AI drug discovery platform repurposes drugs across multiple therapeutic areas.
Outcomes: faster availability of treatments for emerging diseases, lower cost than novel drug development, expanded therapeutic options for rare diseases.
Implementation challenges
Five challenges to plan for in bioinformatics ML deployments:
1. Data heterogeneity and standardization
Bioinformatics data spans multiple modalities (sequencing, imaging, structured clinical data, unstructured notes), formats (FASTQ, BAM, VCF, CRAM, custom institutional formats), and scales (single-cell to population genomics). Standardization and harmonization are substantial engineering work — often consuming 40-50% of project budget.
Mitigation: invest in data infrastructure before ML modeling. Use established standards (BIDS for neuroimaging, OMOP for clinical data, FAIR principles for research data). Partner with data engineering teams experienced in scientific data formats.
2. Limited labeled data
Many bioinformatics tasks have limited labeled data — rare diseases, novel drug targets, specific patient populations. Limited samples constrain model accuracy and generalization.
Mitigation: transfer learning from foundation models (BioBERT, AlphaFold), few-shot learning, synthetic data generation, multi-task learning across related problems, federated learning across institutions to expand effective dataset size.
3. Reproducibility and interpretability
Scientific research requires reproducibility; clinical applications require interpretability. Black-box ML models struggle with both.
Mitigation: version-controlled data, models, and pipelines. Containerized analysis environments (Docker, Singularity for HPC). Interpretability tooling (SHAP, attention visualization, GradCAM for vision models). Mechanistic interpretability research for foundation models in bioinformatics.
4. Regulatory pathway
Clinical and pharmaceutical applications face strict regulatory oversight (FDA, EMA, jurisdiction-specific authorities). ML-based tools claiming clinical decision support, diagnostic accuracy, or therapeutic applications need formal validation.
Mitigation: scope projects below regulatory threshold for early validation. Engage regulatory experts during architecture design. Plan for SaMD pathway timeline (12-24 months for FDA 510(k) clearance) when relevant.
5. Integration with experimental workflows
Bioinformatics ML doesn't exist in isolation — it's part of broader experimental and clinical workflows. Integration with lab equipment, LIMS systems, EHR systems, regulatory documentation pipelines is substantial work.
Mitigation: treat integration as engineering work upfront, not as afterthought. Partner with experimentalists and clinicians as design collaborators, not just users. Plan for ongoing maintenance as instrument software and protocols evolve.
What's deployable today vs what's still research
Production-ready in 2026:
- Protein structure prediction (AlphaFold-class models)
- Genomics variant calling and annotation
- Drug-target interaction prediction
- Single-cell genomics analysis pipelines
- ML-augmented CRISPR guide design
- Literature mining and knowledge graph construction
Pilot-stage requiring clinical validation:
- ML-driven personalized treatment recommendation
- Multi-omics integration for disease subtyping
- Foundation model-driven drug discovery
- AI-augmented clinical trial design
Research-stage, not yet production-ready:
- Fully autonomous drug discovery without human review
- Generative AI for novel protein design at clinical scale
- Real-time ML guidance during experimental procedures
- AI-driven hypothesis generation as primary research methodology
Final framing
AI and ML in bioinformatics aren't research curiosities — they're production infrastructure underlying modern genomics research, drug discovery, precision medicine, and computational biology. The Nobel Prize for AlphaFold marked a turning point: AI is now central to biological discovery, not adjacent to it.
The teams advancing the field are deploying disciplined ML pipelines: rigorous data infrastructure, validated models, interpretability tooling, integration with experimental workflows, and operational discipline that supports reproducible science. The gap between organizations effectively deploying bioinformatics AI and those running expensive pilots is widening.
Ready to scope a bioinformatics AI project? Run the Project Estimator for a deterministic ballpark, or book a 45-minute Discovery with our AI engineers — we'll review your data, scientific goals, and integration requirements to determine the right ML architecture for your bioinformatics use case.
Talk to the team behind this
Building something like this in production?
Our senior engineers ship this kind of work for real teams. 45-minute call, no pitch deck — just architecture, trade-offs, and whether we're the right fit for your problem.











